컴퓨터 구조 - Cache
Size and access time are inversely proportional!
Cache는 사실 이후 프로그래밍을 할 때 언젠가 써볼 수 있는 개념이라고 생각된다. Cache를 이해하기 위해서는 컴퓨터의 작동방법에 대해서 조금 알고 있어야 한다. Cache의 개념은 컴퓨터가 메모리를 접근하는 데 걸리는 시간이 너무 오래 걸려서 생긴 개념이다. 일반적으로 컴퓨터는 하드디스크에 메모리를 저장하는데, 컴퓨터가 매번 어떤 변수에 데이터를 넣거나 어떤 데이터를 불러올 때 하드디스크와 직접 소통하면 시간이 너무 걸릴 수 있는 단점이 존재한다. (하드디스크와 직접 소통하는 것이 머리에 안 그려지면, 컴퓨터가 어떻게 CD에서 정보를 가져오는지 한번 생각하면 된다. CD를 물리적으로 돌려서 정보를 가져오는데, 이걸 매번 한다고 생각하면...😱) 그래서 생긴 개념이 Cache이다.
Cache는 컴퓨터가 자주 접근하는 메모리를 일단 임시로 저장하는 table이라고 보면 된다. 변수에 대한 업데이트가 일어나면 하드디스크에 직접 수정사항을 변경하는 것이 아니라 일단 해당 table에 그 수정사항을 반영하는 것이다. Cache는 일단 새로 접근되는 메모리를 다 table에 추가할 것이다. 하지만, 어떤 row들은 얼마 시간 후에 접근이 안 될 것이고 Cache table 또한 꽉 찰 것이다(Cache는 하드디스크보다 용량이 클 순 없으니... Size와 access time은 반비례한다는 사실!). 이런 경우, 최근에 가장 덜 접근된 row를 추방할 것이다. 수업시간 때 배운 대부분 cache의 구조는 이러했다. 1 Valid bit, Tag(address의 상위 bit), Data 가 하나의 line을 구성했다. 이렇게 써 놓으니깐 이해하기 힘들기 때문에 사진을 첨부하겠다.
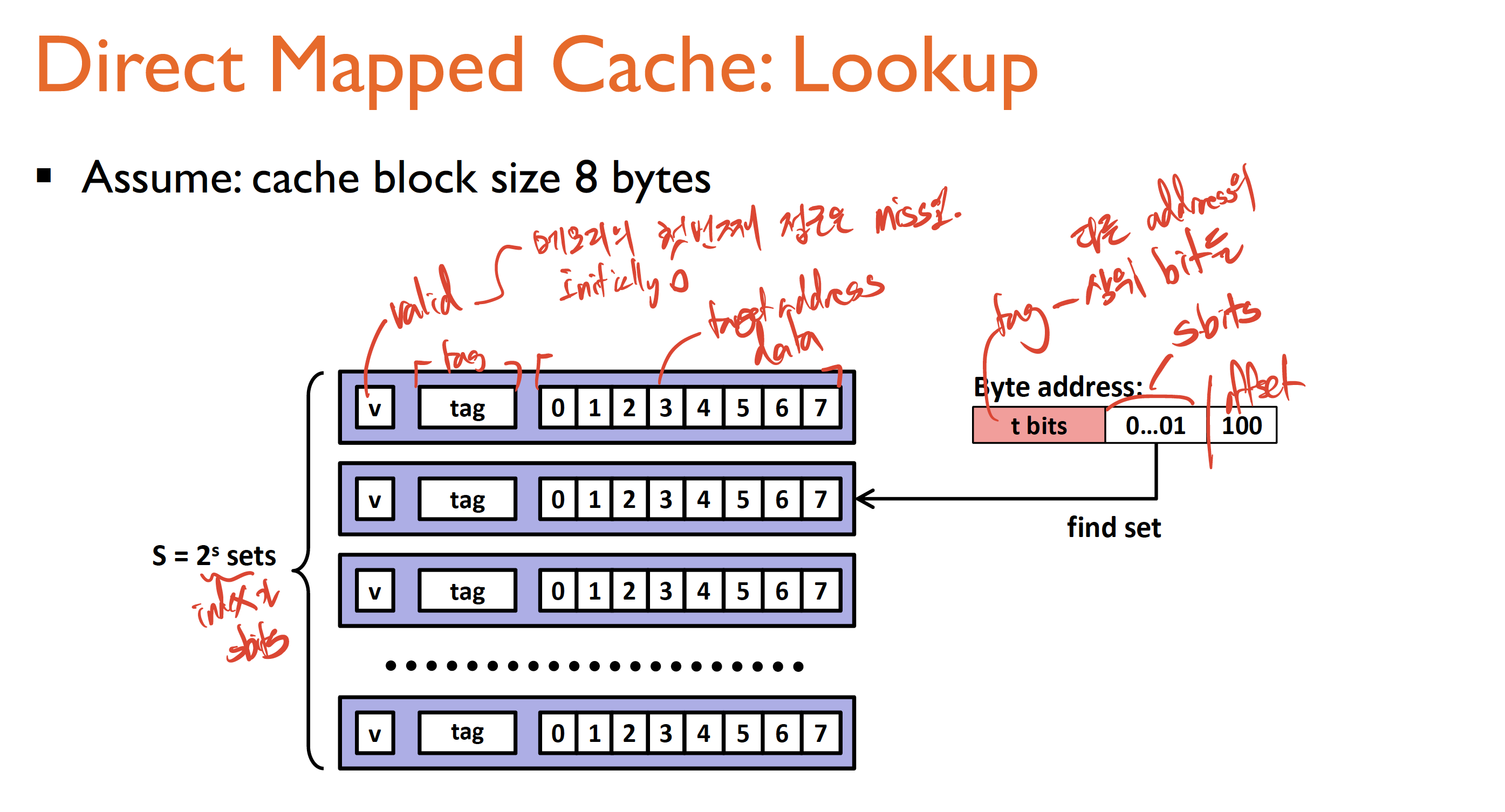
이런 식으로 구성된다. 2^s개의 line이 존재하고 input(table을 위한 열쇠라고도 볼 수 있겠다) address에서 s bit을 활용해 index, line number를 찾고, valid 한지 여부를 확인하고 나머지 offset bit을 활용하여 data를 추출해내는 구조였다. 실제 이런 구조는 memory cache뿐만 아니라 TLB(virtual page number를 physical page number로 바꿔주는 친구), BTB(instruction address로부터 target branch prediction을 바로 찾게 해주는 친구)에도 쓰였다. 이 table은 access time이 훨씬 더 걸리는 더 큰 메모리에 접근하는 시간을 최대한 낮춰주고자 만든 개념이라고 보면 된다.
지금 사진에서는 direct mapped cache가 나와있는데, 이는 하나의 line이 하나의 address에만 대응되게끔 한 단순 cache이다. 이를 조금 더 복잡하게 구현하면 n way set associative cache 도 존재하는 이는, 하나의 line에 n개의 address가 대응될 수 있게 만든 것이다. 다만 이것의 문제는 이제 line안에서 또 찾는 시간이 걸리기 때문에 access time이 더 증가할 수 있는 것이 문제다.
cache는 실제 전체 메모리가 아닌 관계로 항상 원하는 결과를 내놓지 않을 수 있고, 심지어 index를 했는데 알고보니 tag와 달라서 miss가 날 때도 있다. 이 miss가 날 경우 실제 메모리에 접근해서 옳은 값을 가져와 table을 수정해야 하는데 그러한 다양한 고려사항을 수업시간 때 배웠다.